
7.3.2 情感极性与情感词典
7.3.2 情感极性与情感词典
前面的示例已经介绍了常见的情感极性,即将人的情感划分为几种离散取值。常见的包括按照褒义、贬义以及中性来划分,也可以按照“喜怒哀乐”的情绪划分,如喜悦、愤怒、悲哀、恐惧、惊讶等(Xu,et al.2010)。在心理学中,人的情感情绪还有多种模型来评价。例如:
· 美国心理学家罗伯特·普拉契克(Robert Plutchik)教授在1980年提出了“情绪轮”(Wheel of Emotions)模型(Plutchik 2001),如图7.12所示。这个模型包含了8种基本情绪:喜悦(joy)、信任(trust)、恐惧(fear)和惊讶(surprise)及其对立情绪:悲伤(sadness)、厌恶(disgust)、愤怒(anger)和期待(anticipation)。其中一些情绪两两组合还能形成其他情绪,例如喜爱(love)由喜悦与信任构成,其反面悲伤与厌恶则形成懊悔(remorse)。
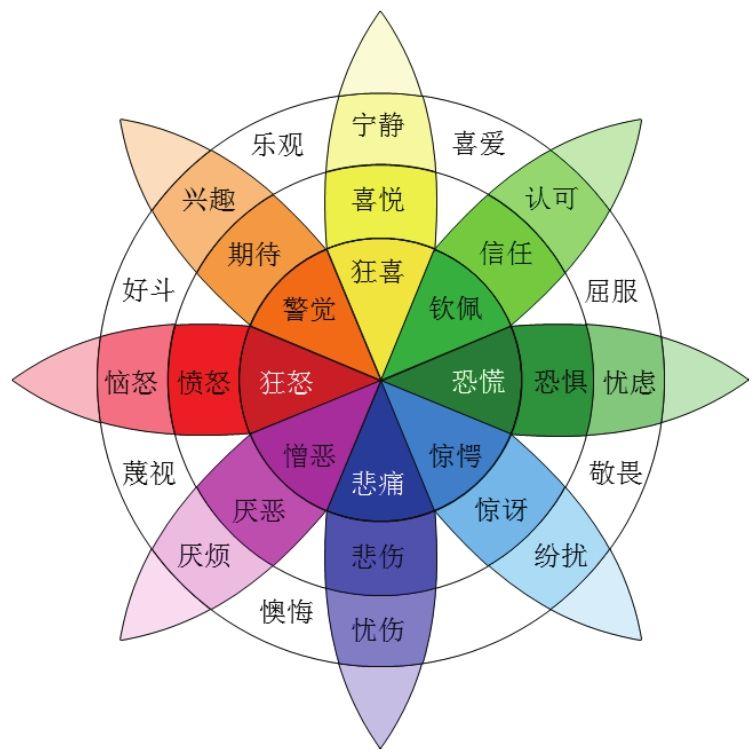
图7.12 “情绪轮”模型
· 美国菲利普·谢弗(Phillip Shaver)教授与谢拉德·帕洛特(W.Gerrod Parrot)教授分别提出了情绪的层次模型(Shaver,et al.1987,Parrot 2001)。在第一层次中,情绪分为喜爱(love)、喜悦(joy)、惊讶(surprise)、愤怒(anger)、悲伤(sadness)和恐惧(fear)6种;每种情绪下分若干子情绪,例如喜爱包括爱慕(affection)、色欲(lust/sexual desire)与渴望(longing),所有子情绪共25个形成第二层次;类似地,第三层次又有100多种情绪。
· 美国心理学家查尔斯·奥斯古德(Charles E.Osgood)将人的情绪按效价(valence)、唤醒度(arousal)、优势度(dominance)来评价(Osgood 1952)。以此为模型,美国佛罗里达大学几位学者整理了千余个英语单词所表达出的情绪程度,得到归一化的情感得分(Bradley&Lang 1999);之后加拿大和比利时的学者在此基础上,进一步整理了近14,000个英语单词、词组的情感得分(Warriner,et al.2013),还分析了不同性别、年龄、教育程度的人群对这些词语的情绪感受程度差别。
可见,当我们把人的情感用较为规范的若干类别来定义后,便可以整理得到各个词语究竟属于哪些情感类别。正如《新华字典》提供字义、《现代汉语词典》提供词义一样,情感词典提供给我们每个词的情感色彩,甚至情感程度。例如,“好”是褒义、“坏”是贬义;“手舞足蹈”比“喜形于色”的褒义程度更大。研究者构建并公开发布的情感词典,虽然规模不大,但可信度高,可以作为情感分析的第一步工具。
然而,词典收录的词条毕竟有限,人工构建费时费力且不现实。那么有没有办法用计算机算法识别词条的情感倾向呢?进一步说,词典收录的词条总是固定的,网络新词那么多(如“给力”、“喜大普奔”等),我们有什么办法能自动扩展词典呢?我们所采用的方法就是从已知到未知:从已知情感的词语出发,通过词语间的相互联系,探索未知情感的词语,如图7.13所示。

图7.13 从已知情感的词语探索未知情感的词语
因此,自动构建(扩展)情感词典可以通过如下三步完成。
1.确定目标:选取合适的候选情感词。在文本中,大部分词语并没有情感倾向。我们需要找出能够表达情感的词或词组(短语),以免混入过多噪声。
2.建立桥梁:通过词汇间的关系,建立合适的度量。通过人工或自动构建的词义网络,我们可以得到候选词语之间的相互联系,作为从已知到未知间的桥梁。
3.传播情感倾向:确定了候选词,相当于架起了桥墩;建立了度量,相当于搭上了桥面;接下来就可以采用适当的方法,从已知情感倾向的词语出发,把它们的情感信息传播出去,使每个未知的候选情感词都被赋予一定的情感倾向。从数学角度而言,倾向性可以用得分(情感得分)来表示,这便可以用数学模型来计算情感倾向了。
这三步之间也是相互联系的。例如,如果目标广(噪声多),选取的度量就需要比较准确,否则错误的信息也会被传播出去,造成干扰;如果候选词语含有很多新词,那么采用的词语关系度量也应当能覆盖这些传统词典未收录的词汇,否则新词就成为了孤立点,无从联系。以下我们首先从第2步出发,针对常见的几种词汇关系进行介绍。
方法一:词义关系
在文本中,词语的情感倾向取决于词义。因此,对于已知情感倾向的词语,它们的近义词应该具有相似的情感倾向、反义词应该具有相反的情感倾向。这样,寻找未知词语情感倾向问题,就转化为寻找相似词语的问题。
在自然语言处理研究界,已有许多学者对词汇的含义、关系进行了梳理,并建立了词义网络。常用的中英文词汇知识库包括如下。
· 英文资源:普林斯顿大学研发的WordNet。它不但收录了大量的词条,而且针对各个词语的不同词性、不同含义,按照相同含义进行分组,形成同义词集合(synset)。不同的同义词集合间也建立了联系。这样,所有词汇形成了一个网络,可以便捷地查询到一个词语某个含义的近义词、上下层蕴涵关系,等等。
· 中文资源:由董振东、董强等学者研发的知网(HowNet)。这也是一个词语含义的关系网络,同时也可以认为是揭示词语概念关系的一个知识网络。不同概念间的同义、反义关系,施事、受事关系等,知网都有所体现。知网还有词条相对应的英文释义,为研究者提供了极大的方便。
有了近义词关系网络,我们可以扩展情感词集。例如我们初始知道“高兴”具有褒义情感,那么它的近义词如“快乐”、“欣喜”等都是褒义的。当然,这样描述比较粗糙,特别是经多次传递后,两个词语间的含义可能不那么接近了,那么其相互影响就应当减弱。利用一些数学模型,可以较好地传播情感倾向(情感得分)。
值得一提的是SentiWordNet(Esuli&Sebastiani 2006,Baccianella,et al.2010)。顾名思义,这是在WordNet基础上计算得到的一个英文情感词典,生成词典的步骤如下。
1.选取种子词集合:从较少的几个明确的褒贬义词语出发,通过WordNet里定义的二元关系(如相同极性的“also-see”或相反极性的“direct antonymy”等关系),扩展这些词语(可控制传播半径),形成褒义和贬义的词语集合,作为“种子”集合。
2.训练分类器:用上述的褒贬种子词集,再加上一个中性种子词集一起,作为训练数据,即训练一个三分类器。由于WordNet定义了同义词集(synset),这个分类器训练的单位不再针对一个个词语,而是针对一个个同义词集。
3.标记其他同义词集:利用上一步得到的分类器,可以对WordNet中所有的同义词集进行标记,得到它们的情感倾向。
4.研究者发现,最佳的分类效果需要训练多个分类器,分别采用不同的传播半径和分类模型,最后由多个分类器投票决定待标记词集的情感倾向。
5.采用随机游走(random walk)模型分别对得到的褒义词集、贬义词集的情感倾向进行调整。当游走过程收敛后,即得到最终结果。
其他一些利用WordNet的工作方法也类似。例如(Kim&Hovy 2004,Hu&Liu 2004),都是选取一些已知情感倾向的动词或形容词作为种子词,利用同义词关系扩展这个集合,或计算与之在WordNet中的共现概率。这样,在WordNet中出现的其他词语,只要被同义词关系覆盖到,都可以计算出一定的情感倾向。
方法二:句法关系
词义关系毕竟是依靠已总结出的关系网络。但在很多时候,一些词语并不能被网络覆盖;还有些词语的用法、词义比较灵活,现有的知识库尚未涵盖。这就需要寻找其他关系。
我们可以利用句子信息来建立词语间的桥梁。在较长的句子中,不同分句间往往有连词作连接。并列连词连接着并列含义的句子;转折连词连接相反含义的句子。因此,两个分句中的词语就可以用连词信息来判断是相近含义还是相反含义。如果我们的语料足够大,那么这些词汇在分句间的联系就有了一定的统计意义,可以作为比较可信的关系度量。
在(Hatzivassiloglou,et al.1997)工作中,作者采用两千多万篇新闻语料。选取形容词作为候选词语,进而利用“and”、“or”、“but”等连词构建词语间的相互联系。这些近义或反义的词对形成了一张图(graph),接下来可以采用优化或聚类的方式,将相近倾向的词语划分为一个个簇;再根据簇内已知情感倾向词语的多少,来标记整个簇内词语的情感倾向。
这种句子间的关系,比起前面的词义关系来说要弱了许多,会有更多的噪声。但对于大的数据规模而言,真实的词语关系会多次出现在语料中;不真实的词语关系出现次数较少。因此,这个方法可以在大数据下得到较好的应用。
但如果我们的句子连词较少,各个句子之间的联系并不紧密,我们还能找到词语间关系吗?
方法三:同现关系
研究者们注意到了这样一个现象:表示相同情感倾向的词语更可能共同出现,但相反倾向的词语则较少共同出现(Beineke,et al.2004)。在较大尺度的数据中,这个现象更加突出。在大数据时代,语料相对是充足的,因此利用“共同出现”——即“同现”这个特点便可以计算词语的情感倾向。
可以看出,同现关系比前面两者更弱,噪声更多。因此,一方面我们可以增强同现关系的可靠性;另一方面我们可以在倾向性得分传播时,予以过滤,以滤除噪声。
对于增强同现关系的方法,通常的做法是扩大语料规模,使同现关系更可靠。但是语料扩大会导致计算能力需求的攀升,而且并不是所有噪声都能被降低。因此,还可以采取的方法如下。
· 选取一个适当的“窗口”,即一个词的上下文中,相邻k个以内的词才算是同现;或者按照词间距离,将其同现的权重逐渐衰减——这其实表明同现关系不能无边无沿。
· 采用适当的方法衡量同现关系。我们不能仅仅根据同现次数的多少来认为两个词之间是有联系的。例如“的”字频繁地跟很多词同现,但这并不能说明其独特性。这时除了用概率估计外,还可以采用“点对互信息”(Pointwise Mutual Information,PMI)来衡量两个词(或词组)之间的相关性:
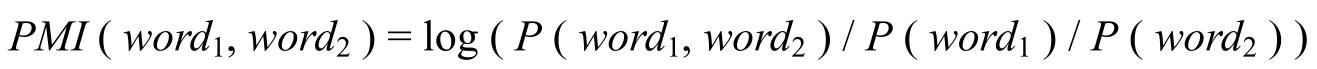
例如文献(Turney 2002)中利用下式来计算一个短语的褒贬程度:

这表示短语的情感极性是它跟“好”词相关程度与它跟“坏”词相关程度之差。
利用“词嵌入”(word embedding)方法,将每个词用多维向量表示。通过学习算法,可以使得相似含义的词语向量距离较近,从而发现相似词语。这一方法把成千上万的词汇(高维空间)转化为低维向量表示,便于计算和挖掘词义。Google公司的研究员们提出的Word2vec算法是一个经典的例子,可以改善情感分析任务的性能。
对于过滤得分传播的方法,研究者们通常选用适当的算法进行传播计算。
考虑同现关系将词语组成的一个个词对可以构造一个图。之后可以仿照前面的做法来计算候选词语的情感倾向。这里选用的算法需要能对强的关系予以增强、弱的关系予以减弱。例如文献(Serban,et al.2012)中将子图中的完全图(clique)作为强关系;文献(Banea,et al.2008)在每次迭代计算新候选词的情感得分后,采用相似性度量进行过滤,只保留与原始种子集最相似的新词集合。
以上是常见的几种词语度量关系。至于候选情感词的选取,通常和应用问题或语料密切相关。例如上文也提到了,传统文本中通常只采用形容词、动词等词语作为候选情感词。然而在很多评论文本中,一些短语也可能具有整体的情感倾向。文献(Turney 2002)中即定义了若干规则来通过特定词性的词生成候选的情感词组,如表7.3所示。
表7.3 表达情感的短语构成规则(Turney 2002)
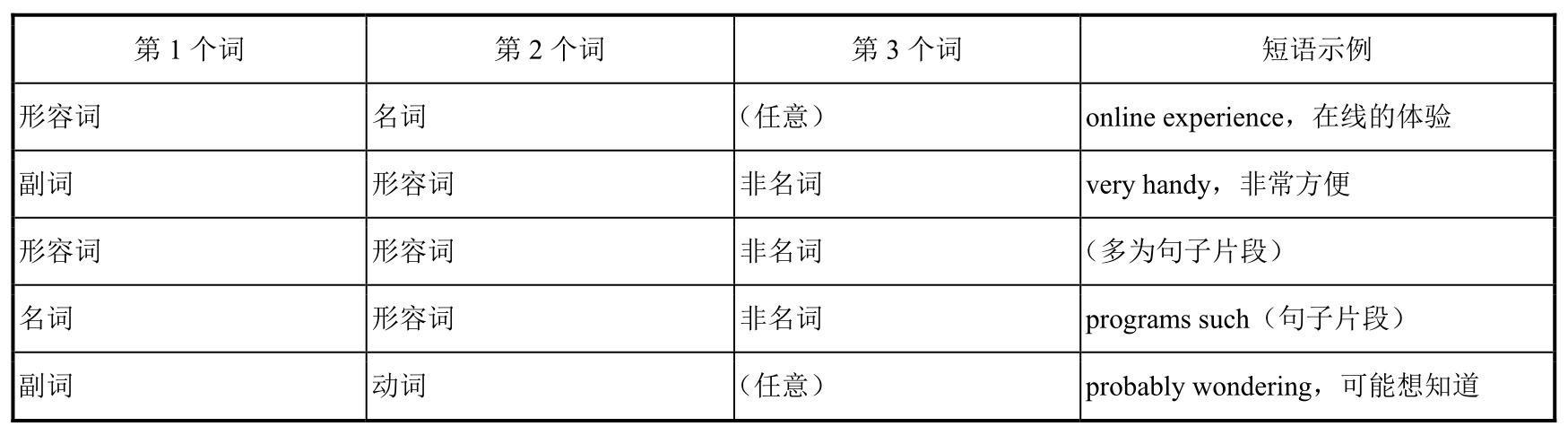
此外,本节开始提到在社交网络类文本中,情感符号也是常见的表达情感倾向的元素。因此情感符号也可以作为情感候选词的一类(崔安颀 2013)。尤其是在微博等互联网新媒体文本中,各式情感符号、情感图标层出不穷,而这些“词”并不为传统词典所涵盖。因此采用前述的基于同现的分析方法可以自动计算得到情感符号的情感倾向,从而帮助对这类新媒体文本进行情感分析。
对于情感得分的传播,由于词义关系构成了图,自然可以采用多种基于图的算法进行计算。除了前文提到的图内聚类方法,常用的算法还有图传播(graph propagation)(Velikovich,et al.2010)与标签传播(label propagation)(Zhu&Ghahramani 2002)等。这两者的基本思想都是从若干种子词出发,每次更新与已有得分词相连的新词得分,使情感得分逐渐传播到全图。两者的区别在于:在标签传播算法中,未知得分词语受到所有与之相连的已知得分词语影响;而在图传播算法中,未知词只受到关系最强的一个已知词影响。如果全图中有许多比较密集的子图,或者图的质量不高,那么采用标签传播算法就会使这些子图涉及的词语受到很强的噪声干扰。因此,需要根据语料、度量方式,选择适当的传播算法。
评论 :01 / 1